
Reinforcement Learning of Multi-Domain Dialog Policies Via Action Embeddings
3rd Conversational AI Workshop at NeurIPS, 2019
PDF Video
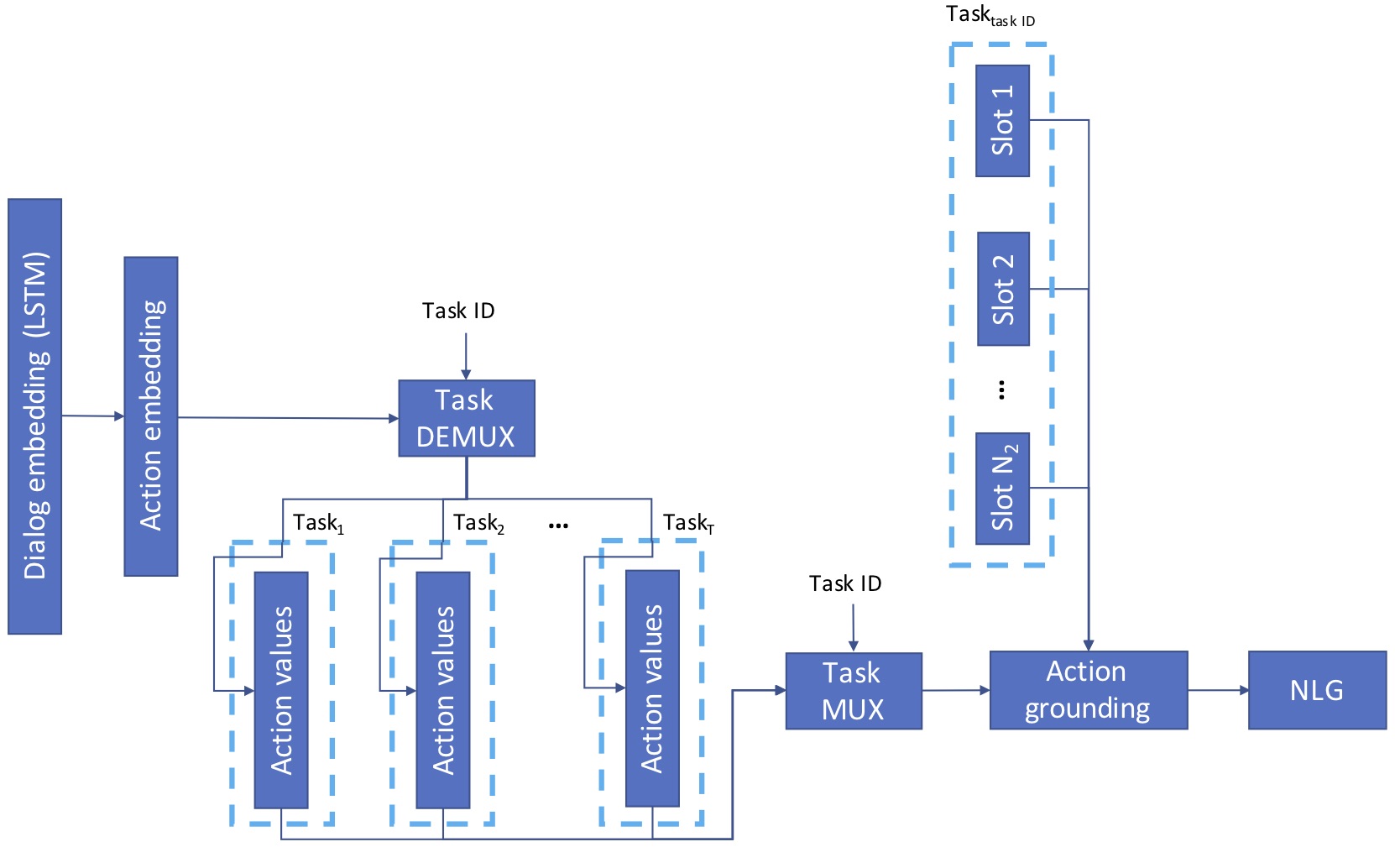
Abstract: Learning task-oriented dialog policies via reinforcement learning typically requires large amounts of interaction with users, which in practice renders such methods unusable for real-world applications. In order to reduce the data requirements, we propose to leverage data from across different dialog domains, thereby reducing the amount of data required from each given domain. In particular, we propose to learn domain-agnostic action embeddings, which capture general-purpose structure that informs the system how to act given the current dialog context, and are then specialized to a specific domain. We show how this approach is capable of learning with significantly less interaction with users, with a reduction of 35% in the number of dialogs required to learn, and to a higher level of proficiency than training separate policies for each domain on a set of simulated domains.
Recommended citation:
@inproceedings{mendez2019reinforcement,
author = {Mendez-Mendez, Jorge and Geramifard, Alborz and Ghavamzadeh, Mohammad and Liu, Bing},
booktitle = {3rd Conversational AI Workshop at Neural Information Processing Systems (ConvAI-NeurIPS)},
title = {Reinforcement Learning of Multi-Domain Dialog Policies Via Action Embeddings},
year = {2019}
}